
Guide to Human-in-the-Loop Machine Learning
Discover how HITL machine learning works and how it addresses AI agents, generative AI risks, and regulatory compliance.
Modern AI systems are capable of handling complex tasks autonomously and producing content at scale. However, as model complexity increases, so too does the demand for reliable AI training data across diverse real-world use cases. McKinsey shows that organizations excelling with AI are much more likely to have clear processes that define when model outputs must be checked and validated by humans (Singla et al. 2026). They are less likely to trust model outputs blindly.
These guardrails matter because even the most advanced AI systems still make mistakes. They may overlook key details or create compliance and reputation risks. More than half of organizations using AI already face these risks and are now turning to a human-in-the-loop (HITL) approach to mitigate them. HITL machine learning improves data quality by combining human judgment with machine efficiency to shape, correct, and govern model behavior. In this article, we’ll explore what HITL machine learning is. We will discuss how it works and where it’s applied in the real world.
What is Human-in-the-Loop machine learning?
HITL machine learning is an iterative feedback process in which humans interact with automated systems to improve decision-making, accuracy, and integrity throughout the AI process. Human feedback helps ML models refine their interpretations, such as adjusting decision boundaries or feature weights. Clear, consistent feedback speeds up learning and improves model accuracy.
Traditionally, automation seeks to eliminate human involvement. But HITL places human judgment at critical junctures, such as handling ambiguous data, reviewing low‑confidence or high‑risk predictions, and reflecting the diversity of human input.
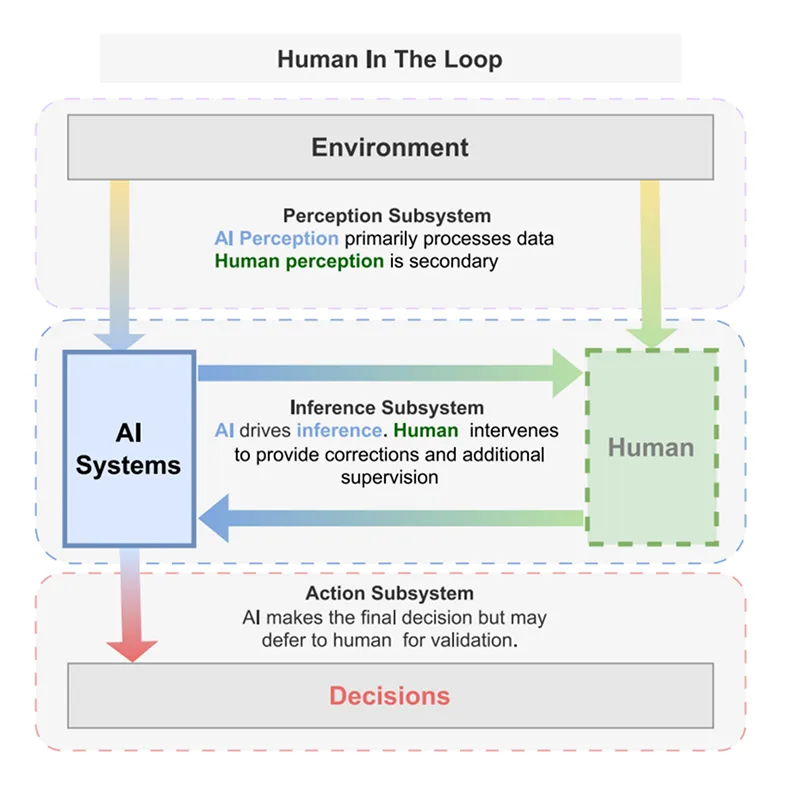
HITL vs. active learning vs. human-over-the-loop (HOTL)
Although these terms are used interchangeably, they have different implications for system design and human involvement.
Key applications and use cases
Human validation remains pivotal to ensure reliable performance across use cases from retrieval-augmented generation (RAG) to image generation. While HITL is industry-agnostic, its application varies depending on data modality (text, image, audio) and the risk profile of the use case.
AI agents and autonomous systems
The increasing use of AI agents has made human oversight an essential part of their design. Without supervision, these agents could take irreversible actions, like approving false transactions or sending legally binding messages. To prevent this, effective systems use policy-based alerts at key decision points.
For example, a claims agent might automatically approve simple cases, but flag claims over $10,000 or those with signs of fraud for human review. This approach reduces the amount of work humans need to do while ensuring that an expert reviews high-stakes decisions. The framework logs every human override, creating training data that improves the agent's performance over time.
Generative AI safety and content moderation
Language models generate content at scale but suffer from hallucinations (produce inaccurate output with confidence), bias, and policy violations. Human review processes are important to keep things in check. People check AI-generated marketing messages to ensure they are on-brand, verify financial reports for accuracy, and moderate responses in chatbots meant for users.
Even state-of-the-art multimodal models remain vulnerable to adversarial prompting and are capable of outputting harmful content in everyday scenarios. Learn more in Appen's latest multimodal red teaming research.
Computer vision
HITL is non-negotiable in high-risk situations. Computer vision models can pre-screen medical images, flagging potential abnormalities. Feeding corrections from licensed radiologists back into model training improves accuracy over time.
Similarly, autonomous vehicles rely on HITL for annotating safety-critical scenarios. Human experts review edge cases such as near-miss accidents and construction zone navigation that are not common in training data but are vital for safety. This focused data annotation helps the AI learn from high-risk, edge cases as well as common ones.
How HITL works in practice
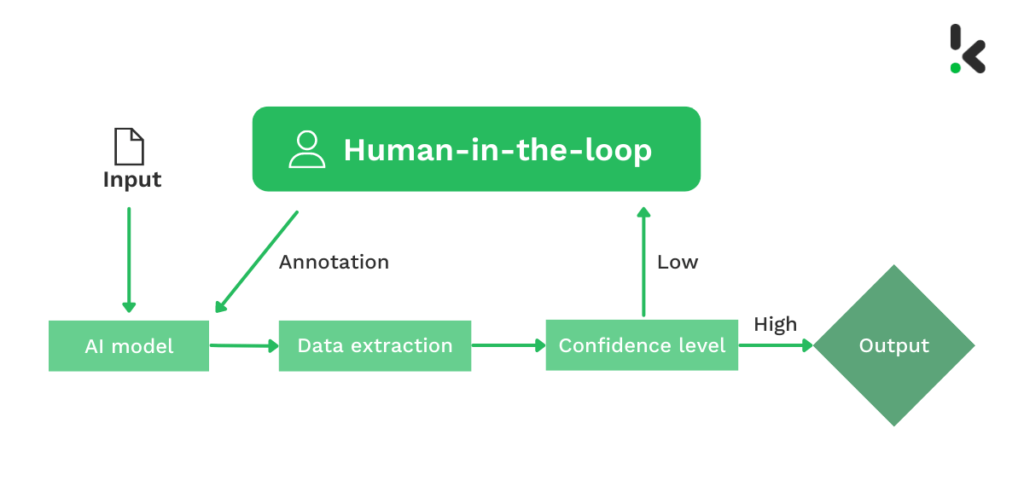
The HITL process begins when an AI model makes an initial guess about data, like identifying an image or labeling audio data, and gives a confidence score (as an output). Instead of reviewing every piece, the system uses confidence-based routing to filter the workload.
The high-confidence predictions are automated, while less certain or tricky cases are flagged and sent to a human for review. This way, humans focus on complex scenarios where the model is most likely to fail.
A human expert then checks the prediction of the flagged case and makes corrections if needed, such as adjusting a bounding box or editing a generated response. And the model then ingests these corrections to understand its blind spots, updating its parameters to better handle similar cases on its own in the future.
Over time, this evaluation cycle of prediction and correction improves model accuracy and decreases the number of cases needing manual intervention. As a result, the system becomes smarter and more efficient with each iteration.
Best practices for HITL systems
To maximize the ROI of your HITL investment, follow these industry best practices:
- Treat humans as experts, not cogs: The quality of your data reflects the quality of your workforce's experience. Provide feedback to annotators when they make mistakes so they can learn from it. If the task is subjective, allow annotators to flag "ambiguous" items or collect multiple ratings.
- Iterate on instructions: Your first set of guidelines will be imperfect. Run a pilot batch, analyze the confusion matrix (where humans and models disagree), and update the guidelines. If humans consistently disagree on a specific label, your definition of that label is likely unclear.
- Manage cognitive load: Decision fatigue sets in quickly. Don't ask someone to label 50 objects in a single picture; break the task into smaller parts. Rotate tasks to keep engagement high. A tired human often produces lower-quality data than no data at all.
- Prioritize diversity to mitigate bias: If your annotators are all from a single demographic, your model will inherit their cultural biases. Ensure your human loop represents the diversity of the real world your model will operate in, since this is critical for natural language processing (NLP) and facial recognition tasks.
How Appen supports HITL at scale
Building a HITL pipeline in-house requires managing software, payments, quality assurance, and recruitment across different time zones and languages. This is where Appen serves as your strategic partner. With 30 years of experience supporting leading AI model builders, Appen combines enterprise AI Data Platform (ADAP) with access to a crowd of over 1 million contributors across 200+ countries speaking 500+ languages. From multilingual AI audio transcription to subject matter expertise in finance or coding, Appen can spin up a qualified team on demand to support next-gen AI model development.
Contact us to speak with an expert and find out how reliable HITL data can improve your AI models.
References
Singla, A., Sukharevsky, A., Yee, L. A., & Chui, M. (2025, November 5). The state of AI in 2025: Agents, Innovation, and transformation. McKinsey & Company. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai