



Last week, the Appen team exhibited at the 2017 Big Data Innovation Summit in San Francisco where we spoke with a wide variety of firms representing industries from Aerospace to Financial Services to Retail about their data challenges, and ways to use their data as a strategic asset for their businesses.While several companies we spoke with are already using machine learning to further their businesses, others have yet to venture into the field despite their acknowledgement of its potential benefits. According to speaker Jay Yonamine, Head of Data Science - Global Patents at Google, if companies could implement even small, incremental efficiencies using machine learning, they could realize large savings and better outcomes for customers. Yonamine provided an example in the Legal industry where even just 1% of added efficiency could provide greater access to legal representation and less bureaucracy, and in Healthcare where the same amount of efficiency can provide better access to care for people who might not have had access beforehand.Organizations may be struggling with where to begin with machine learning when they consider the vast amounts of unstructured data they produce, including emails, texts, presentations, videos and more. Nav Kesher, Head of Data Science at Facebook highlighted this issue in his presentation “Making Sense of Unstructured Data”, explaining that 80% of all digital data is unstructured, and is growing at 60% compound annual growth rate. He used the iceberg analogy to demonstrate the vast amount of data that organizations have yet to tackle, and stressed the importance of analyzing this data to generate actionable insights.Kesher outlined a clear process for making sense of unstructured data:Step 1: Establish a business goalHe underscored the importance of articulating a clear business goal in 10 words or less. For example, “How many orders should I expect this holiday season?”. Connect your business goals to your analysis goals and avoid scope creep for the best results.Step 2: Evaluate data sourcesWhat data do you need to answer your questions? How much data do you need to address your business goals, and how many different data types should be analyzed?Step 3: Evaluate your data stack and analysis toolsKesher recommended using a “data lake” as opposed to a data warehouse, since data lakes contain more raw data that can be crunched to figure out which machine learning algorithm to apply. Make sure you also think of the scalability of your stack. Then determine the analysis tools needed based on the type of unstructured data you are looking at.In terms of analytics methods, Kesher reviewed the following approaches that he uses on a consistent basis:He explained that predictive and prescriptive methods are where data scientists can add the most value since they can use these methods to create models for what might happen in the future as well as recommendations for upper management.Step 4: Data Cleanup“This is the bane of my life”, Kesher explained as he used the following slide to illustrate the many ways that a data point as simple as a date can be written. But this data must be cleaned up for the model to work:
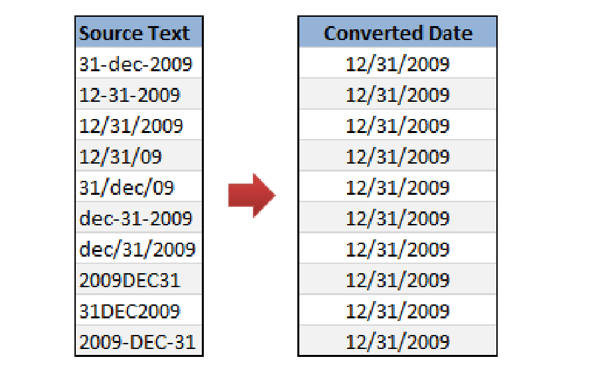
“If one thing breaks, the whole model breaks…you don’t know how painful (machine learning) is until you get to the final step…I did all of the work for two days just to clean up the data.”Step 5: Data ModelingAre you ok with 90% accuracy? How accurate do you need to be to meet your business goals. Every Data Scientist should ask themselves this question. Even 70% accuracy may be ok if it allows you to move fast.Step 6: Data VisualizationAccording to Kesher, data visualization is “an art that every Data Scientist needs to know”. Become a good storyteller. Use your model to inform your stakeholders on the impact that your findings can have on the business. Make your insights simple and back your analysis up with data. And make sure that your work is reproducible so that the next Data Scientist can build on it rather than having to start over.Unstructured data can be used to build a competitive advantage for organizations that take steps to allocate resources to this effort. Data cleanup is a key step in the process and critical for the models to produce meaningful insights. Whether you are working with text, speech, or image data, Appen can help you annotate it using our global, curated crowd. We work with the leading technology companies to provide high quality training data for their machine learning platforms, and would invite the opportunity to discuss your specific data needs. Contact us today.